![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
14 Cards in this Set
- Front
- Back
|
Problems in traditional computing |
Storing huge data, storing heterogeneous data, fast processing
|
|
|
Solutions by Hadoop |
Data stored distributed in datanodes, can store variety of data, move CPU processing logic to all nodes and process parallely |
|
|
Hadoop definition |
Open source software framework used for storing and processing BD in a distributed manner on large clusters of commodity hardware |
|
|
Features of Hadoop |
Reliable, flexible, scalable, economical |
|
|
HDFS definition |
Java based distributed file system that allows to store BD across multiple nodes in a Hadoop cluster. Provided as a storage service. |
|
|
Advantages of HDFS |
Distributed storage, distributed and parallel computation, horizontal scalability (no added hardware; add new nodes to existing cluster on the go) |
|
|
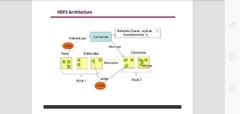
HDFS architecture |

|
|
|
HDFS architecture definition |
HDFS is block structured FS where each file divided into predetermined sized blocks kept in one or more datanodes |
|
|
Namenode or Master node |
Maintains and manages the slave nodes; highly available server that manages FS namespace and access to files by clients. Never contains user data. Records metadata of all files in the cluster, and modifications to it. Records all blocks in HDFS and their location. Takes care of replication factor of blocks. Regularly receives heartbeat and block report from all datanodes to ensure they are alive. In case datanode fails, chooses other datanode as replica and balances disk storage. |
|
|
Datanode (a commodity hardware) |
A block server that stores data in its local file. Slave daemons that run on each slave machine. Store actual data. Perform low level read-write requests from clients. Sends heartbeat to namenode periodically. |
|
|
Secondary node ( checkpoint node) |
Works as helper daemon to namenode. Performs regular checkpoints on HDFS. Reads all metadata from RAM of namenodes and writes to HDD. |
|
|
Blocks |
Smallest continuous location on HDD where data is stored. In any FS, file is stored as a collection of blocks. Block size is generally kept high in HDFS because data is huge (in terms of PB or YB). |
|
|
Replication management |

Blocks are replicated to provide fault tolerance. Default=3. Namenodes control replication factor; if a block is over or under replicated, it adds or deletes as needed. |
|
|
HDFS architecture overall |
|