![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
55 Cards in this Set
- Front
- Back
|
Give two examples that uses Supervised Learning
|
- Regression
- Classification |
|
|
Give two examples that uses Unsupervised Learning
|
- Clustering
- Data Compression |
|
|
Give two examples that uses Reinforced Learning
|
- Behavior Selection
- Planning |
|
|
Give one example that uses Evolutionary Learning
|
- General Purpose Optimization
|
|
|
Give some examples on where machine learning is used
|
- Speech recognition
- Image recognition - Natural language processing - Autonomous robots - Spam-filter for e-mail |
|
|
Where is machine learning useful?
|
- A pattern exist
- Data available for training - Hard/impossible to define rules mathematically |
|
|
Describe Nearest Neighbour
|
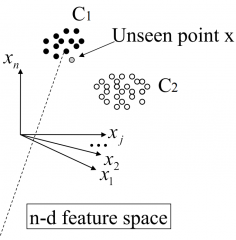
Example - N1 samples of class C1 - N2 samples of class C2 - Want to classify x- Compute distance to all the N1 + N2 samples -> Find the nearest neighbour -> Classify x to the same class |
|
|
Describe k-NN
|
- Compute the distance from all samples to the new data x
- Pick the k nearest neighbours to x -> Majority vote to classy x |
|
|
Give three pros of k-NN
|
- Simple (only one parameter k)
- Applicable to multi-class problems - Good performance, effective in low dimension data |
|
|
Gives two cons of k-NN
|
- Costly to compute distance to search for the nearest
- Memory requirement: must store the whole training set |
|
|
The Shannon information content of an outcome is
|
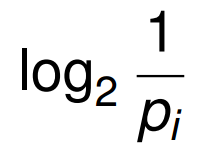
|
|
|
What is entropy?
|
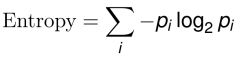
- Measure of uncertainty (unpredictability)
|
|
|
Information Gain |

|
|
|
How do you train a Decision Tree |
1. Choose the best question (according to information gain [most gain]), and split the input data into subsets. 2. Terminate: call branches with unique class labels leaves (no need for further questions) 3. Grow: Recursively extend other branches (with subsets bearing mixture of labels) |
|
|
Decision Tree Example: Entropy Coin Toss |

|
|
|
Decision Tree Example: Entropy Dice |

|
|
|
Decision Tree Example: Entropy Fake Dice |

|
|
|
Decision Tree: Give the greedy algorithm to choose a question |
Choose the attribute which tells the most about the answer - In sum we need to find good questions to ask. (more than one attribute could be involved in one question) |
|
|
What is Gini impurity? |

|
|
|
What is overfitting? |
- When the learned model is overly specialized for the training samples. - Good results on training data, but generalizes poor |
|
|
When does overfitting occur? |
- Non-representative samples - Noisy examples - Too complex model |
|
|
Occam's principle (Occam's razor) |
"Entities should not be multiplied beyond necessity" The simplest explanation compatible with data tends to be the right one |
|
|
How should you use your training data to reduce overfitting? |
Separate the available data into two sets - Training set, T: To form the learning model - Validation set, V: To evaluate the accuracy of the model (V needs to be large enough to provide with statistically meaningful instances) |
|
|
Why should you split up the data set into a training set and a validation set? |
- The training may be misled by random errors, but the validation set is unlikely to exhibit the same random fluctuations. - The validation set provides a safety check against overfitting. |
|
|
Explain Reduced-Error Pruning |
Split the data into training and validation set Do until further pruning is harmful: - Evaluate the impact of pruning each possible node (and those below it) with the validation set - Greedily remove the one that most improves the accuracy of the validation set Produce the smallest version of the most accurate subtree |
|
|
When extending the decision tree how do you avoid overfitting? |
- Stop growing the tree when the data split is no longer statistically significant.
- Grow full tree then post-prune (e.g. with reduced-error pruning) |
|
|
Overfitting: Graph |
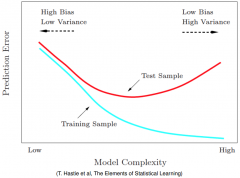
|
|
|
What are some issues that occur in higher dimensions? |
- Easy problems in low-dimensions are harder in high-dimensions -- Training more complex model with limited sample data - In high dimensions everything is far from everything else. -- Issues i nearest neighbours. |
|
|
Mean square error (MSE) |

|
|
|
Bias of a classifier |
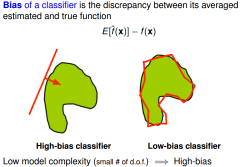
|
|
|
Variance of a classifier |

|
|
|
Residual sum of squares (RSS) |
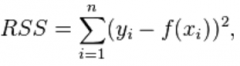
The sum of squared errors of prediction f(x) - the predicted value y - the actual value |
|
|
What is Recursive Binary Splitting and how does it work? |
A top-down greedy algorithm that splits the predictor space. - A split creates two new branches. - The greedy part is that at each split, the best split is made at that stage, rather than looking ahead and see if another split would lead to a better tree. - This continues for each new branch created until a stopping criteria is reached. |
|
|
Linear Regression function |
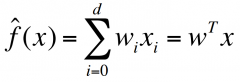
|
|
|
Mean square error |
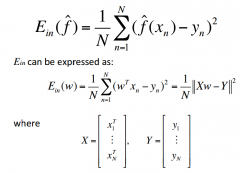
|
|
|
Regression: RSS (residual sum of squares) |

|
|
|
What is RANSAC? |
It stands for RANdom SAmpling Consensus. It's an algorithm to find a robust fit of model for a data set that contains outliers |
|
|
Expain the RANSAC algorithm |
Algorithm (i) Randomly select a sample of s data points from S andinstantiate the model from this subset. (ii) Determine the set of data points Si which are within a distancethreshold t of the model. The set Si is the consensus set ofsamples and defines the inliers of S. (iii) If the subset of Si is greater than some threshold T, re-estimatethe model using all the points in Si and terminate (iv) If the size of Si is less than T, select a new subset and repeatthe above. (v) After N trials the largest consensus set Si is selected, and themodel is re-estimated using all the points in the subset Si. |
|
|
k-NN Regression (non-parametric) |

|
|
|
Example: k-NN regression |
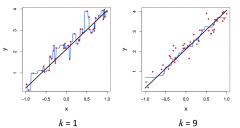
|
|
|
Give two examples of regression + regularization |
- Ridge Regression - The Lasso |
|
|
Ridge Regression |

|
|
|
The Lasso (Least absolute shrinkage and selection operator) |

|
|
|
What is Heuristics? |
Experience-based techniques for problem solving, learning, anddiscovery that give a solution which is not guaranteed to beoptimal (Wikipedia) |
|
|
Naive Bayes: What is the function of MAP estimate of y. |
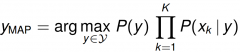
It returns the y with the highest probability |
|
|
Bayes Rule names: |

|
|
|
Bayes Rule: |
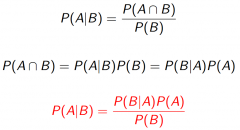
|
|
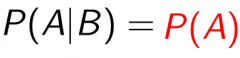
What does it mean!? |

A and B are independent from each other |
|
|
Bayes Rule for ML |

|
|
|
What is Bayesian learning? |

|
|
|
What is Bayes Inference? |
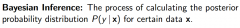
|
|
|
When is Maximum Likelihood Estimate useful? |
Useful if we do not know prior distribution or if it is uniform. |
|
|
Why can't the Maximal Margin Classifier be used on most data sets? |
Since it requires the classes to be separable by a linear boundary |
|
|
Give two examples of common kernels and their functions |
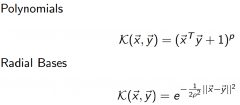
|
|
|
Support vector machine function |
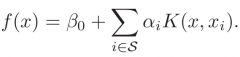
Where S is the set of support vectors and K is the kernel function |